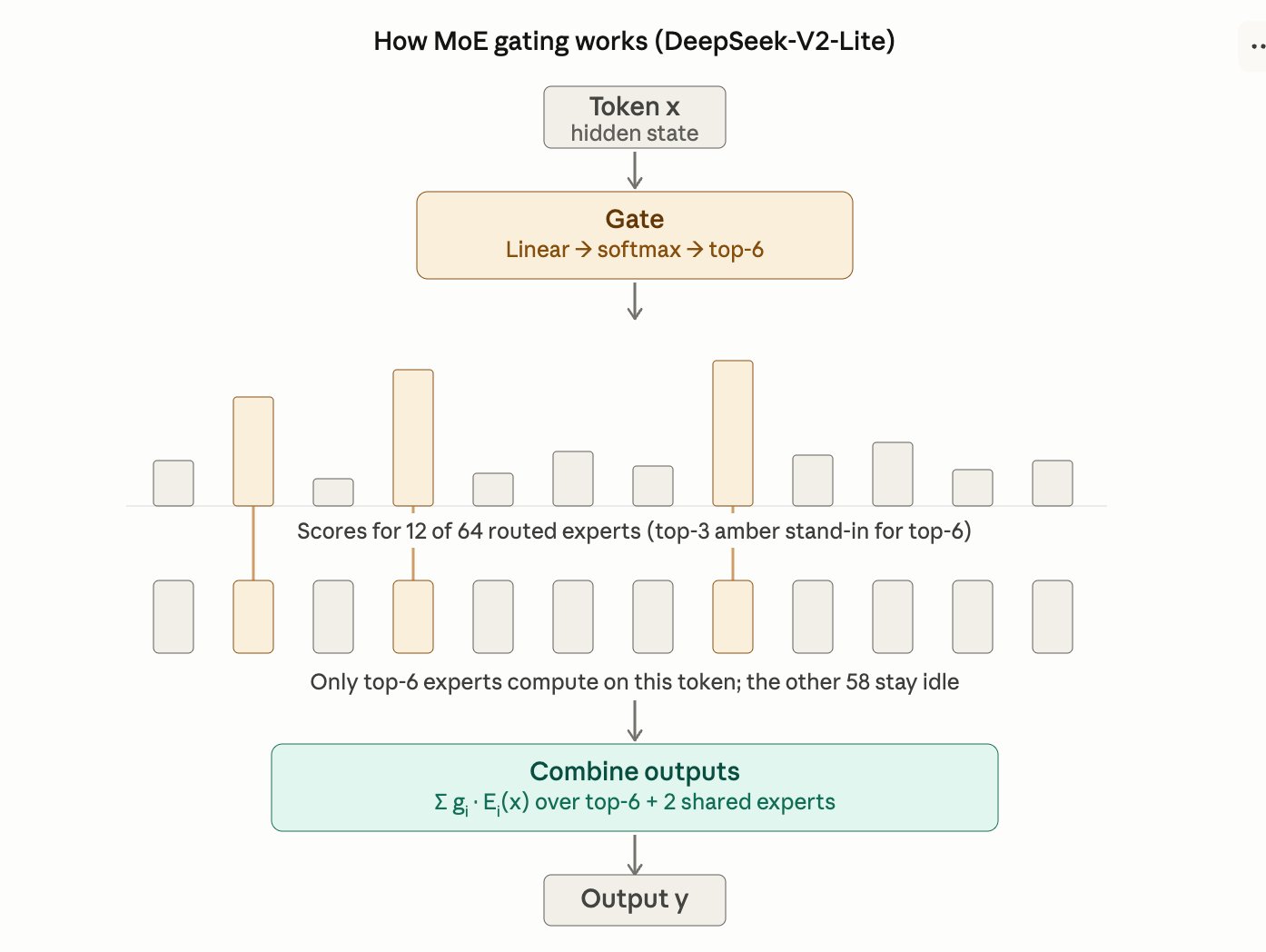
Where the failures live: a mid-network band
Cross-observer attribution identifies layers {6, 7, 8, 10, 13} as failure-carrying.
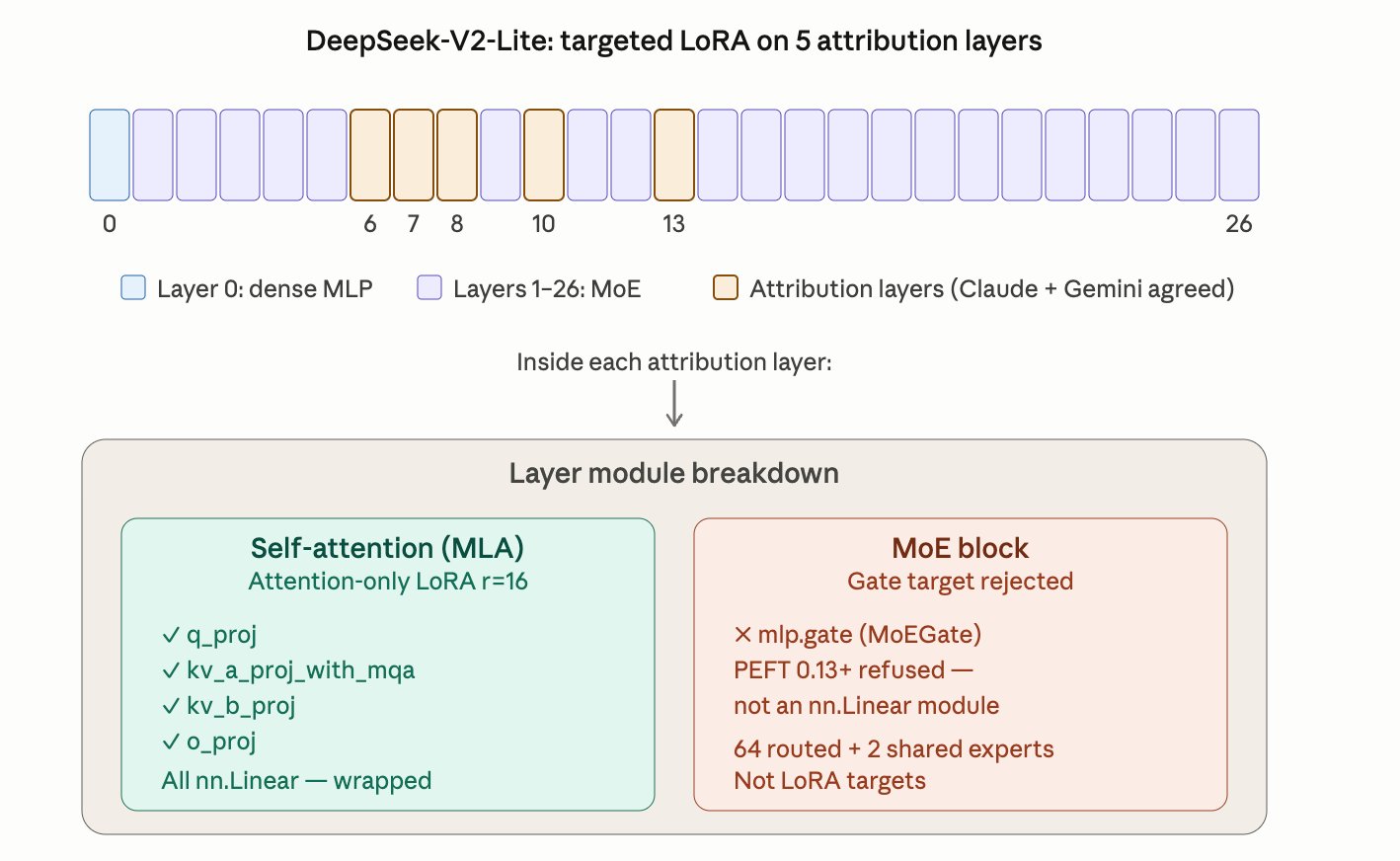
DeepSeek-V2-Lite is 27 layers deep. Layer 0 is a dense MLP; layers 1–26 are MoE blocks. The attribution layers {6, 7, 8, 10, 13} form a non-contiguous cluster around the middle of the network — early-mid through mid-depth, with one gap at layer 9 and a longer gap before 13.
This is consistent with the literature view that mid-layers in transformer-based reasoners do the bulk of the cross-token information mixing where reasoning errors compound. Early layers handle tokenization and lexical features; late layers project back to vocabulary; the middle is where the actual reasoning gets composed and is where it breaks.
The crucial detail: Claude Sonnet 4.5 and Gemini 2.5 Pro independently flagged the same band. That two-observer agreement is what made these layers training targets, rather than any single auditor's opinion. A single LLM auditor could be biased; agreement between two independent ones is much harder to fake.
q_proj, kv_a_proj_with_mqa, kv_b_proj, o_proj. The MoE gate was a target too — but PEFT refused to wrap it. See section 02.